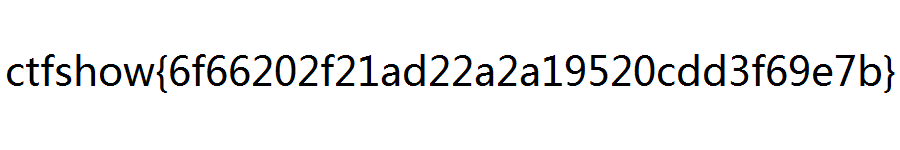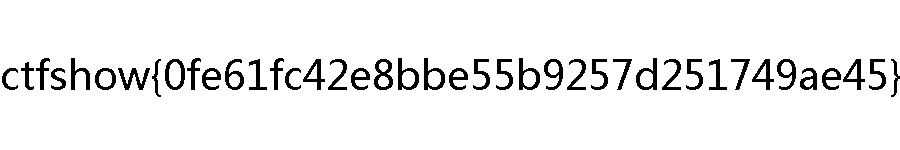ctfshow_misc入门
想了一下还是觉得先把这里写完,后面可能着重去 re 或者 pwn 了?
不过如果可以,我还是希望 misc + re 两手抓
misc1 附件打开后就是一个flag:ctfshow{22f1fb91fc4169f1c9411ce632a0ed8d}
misc2 拿到一个txt文件,文件头是 89 50 4E 47 ,所以将后缀改为 png 即可。
ctfshow{6f66202f21ad22a2a19520cdd3f69e7b}
misc3 是一个 bpg 图片文件,下载 Honeyview 即可查看。
ctfshow{aade771916df7cde3009c0e631f9910d}
misc4 拿到了多个附件,用 010 查看文件头可知是后缀名被修改。
1 2 3 4 5 6 png: 89 50 4E 47 0D 0A 1A 0A42 4D47 49 46 38 39 61 49 49 2A 00 52 49 46 46 XX XX XX XX 57 45 42 50
根据对应文件头修改后缀即可得到分为多段的 flag 。
ctfshow{4314e2b15ad9a960e7d9d8fcff902da}
misc5 尾部隐写。将图片放入 010 中,搜索 ctf 即可找到:
ctfshow{2a476b4011805f1a8e4b906c8f84083e}
misc6 与 misc5 相同,在 010 中搜索 ctf 即可在中部位置找到flag:
ctfshow{d5e937aefb091d38e70d927b80e1e2ea}
misc7 …
与 misc5、misc6 一样
ctfshow{c5e77c9c289275e3f307362e1ed86bb7}
misc8 在 010 中看不出端倪,于是用 binwalk 检查一下,发现有两个 png 文件。
所以用 foremost 分离一下:
得到两张图片,其中一张为 flag 。
ctfshow{1df0a9a3f709a2605803664b55783687}
这题目直接用 010 把前面一张图片数据删掉后保存,应该也可以。
misc9 放入 010 后搜索即可拿到。
使用 exiftool 也可以找到flag
ctfshow{5c5e819508a3ab1fd823f11e83e93c75}
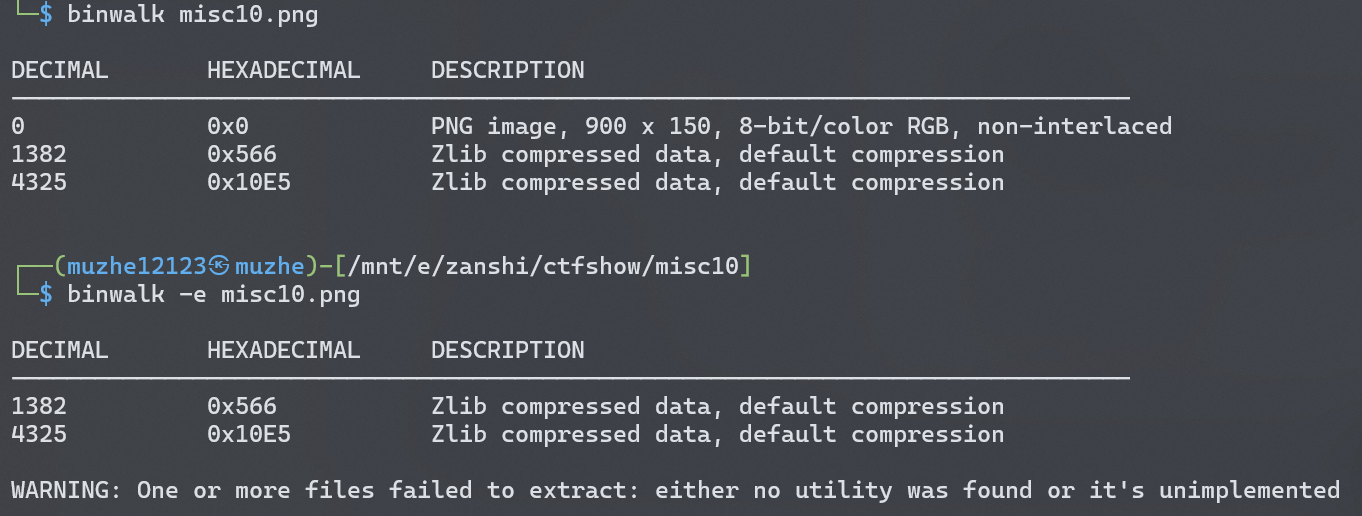
misc10 先用 010 没找到什么信息,于是用 binwalk 看一看,发现有两个 zlib 文件,
于是 binwalk -e misc10.png 拿出来。
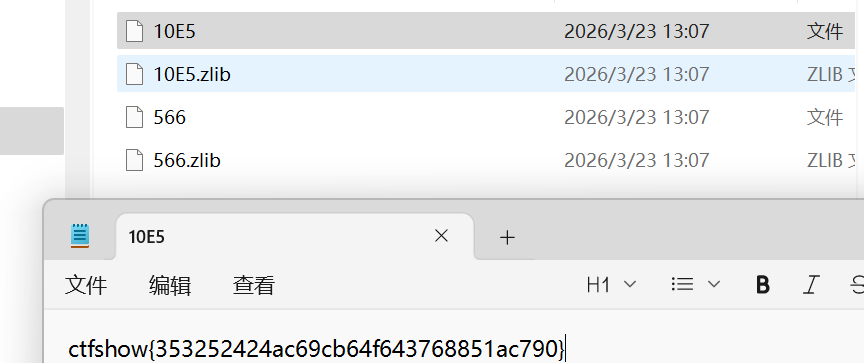
查看 10ES 文件即得flag:
ctfshow{353252424ac69cb64f643768851ac790}
misc11 依旧是先用 010 找东西,发现找不到。
binwalk 得到两个 zlib ,但是提取之后发现文件里没有 flag 。
exiftool 也得不到什么有用的信息。
考虑到附件是一个 png 图片,尝试使用 tweakpng 。
发现它有两个 IDAT 块,将第一个 IDAT 块删除之后,图片出现了 flag :
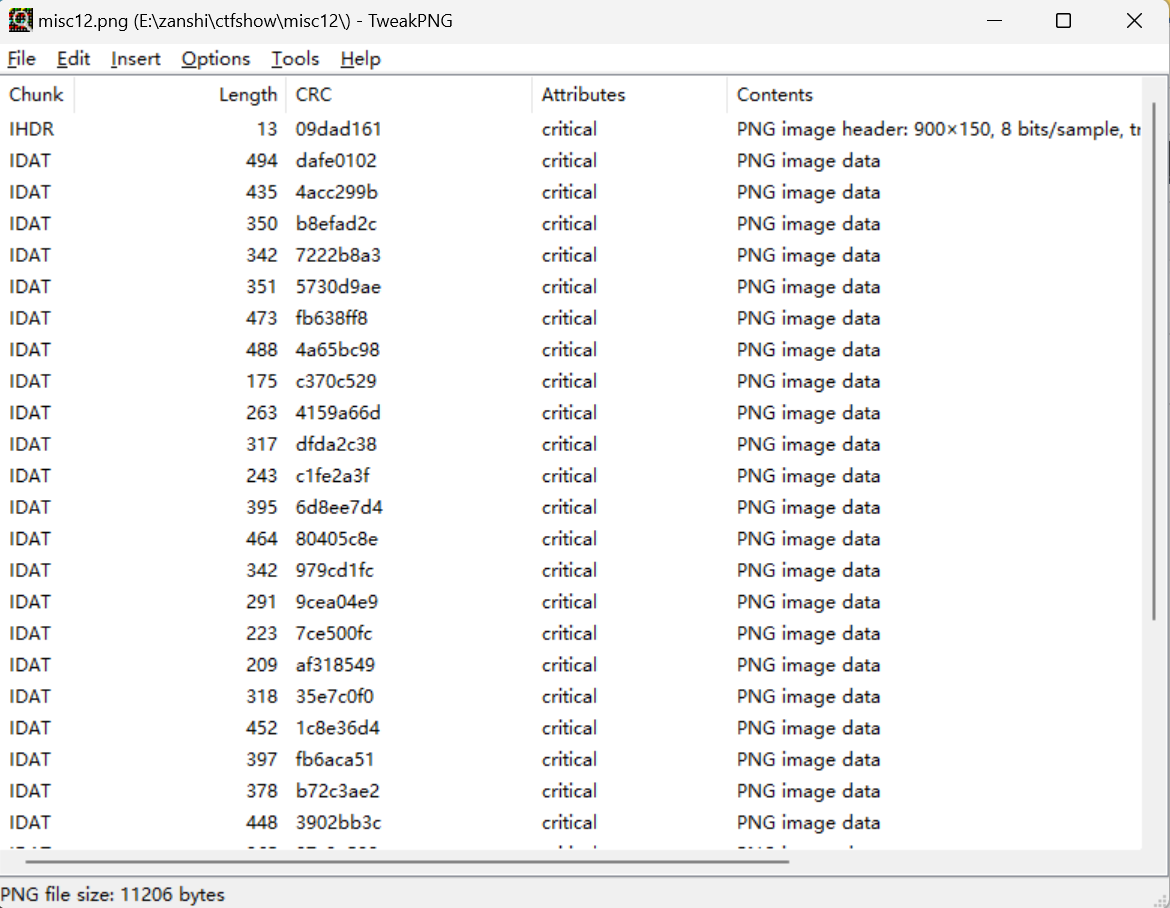
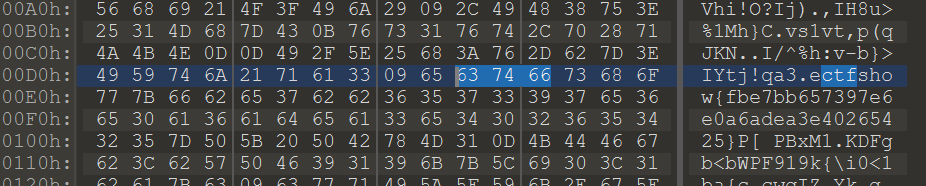
misc12 hyw, 用 tweakpng 打开有一堆 IDAT 块,一个个删除到第 8 个之后,图片出现了 flag 。
misc13 用 010 后在其中找到了 被隔开的 flag ,隔一个字母提取字符后得到 flag :
ctfshow{ae6e3ea48f518b7e42d7de6f412f839a}
misc14 是一个 jpg 文件。
010 里面没有太多信息。
用 binwalk 查看:
发现多张照片。
唔,使用 binwalk -e misc14.jpg 提取失败了,
foremost 提取的文件夹只有 1 张图片 ?
干脆直接在 010 里面搜索 FF D8 , FF D9 ,把前面的图片全部删了,拿到最后的 flag 。
有些人的 wp 中使用的是 dd if=misc14.jpg of=1.jpg skip=2103 bs=1 指令
该指令的意思是:
把 misc14.jpg 从第 2103 个字节开始,直到文件末尾的数据复制到 1.jpg
misc15 给了一个 bmp 文件,但是解法是朴实无华的放入 010 搜索。
misc16 binwalk 后发现一个奇怪的东西放在图片里面:
于是提取后打开 DD4 文件拿到 flag :
misc17 用 binwalk 发现一个 bzip2 文件,提取出来之后发现 flag ,竟然没有 flag !
exiftool 并没有东西。
在 tweakpng 中发现多个 IDAT 块,但是删了没用 ?
删了没用考虑合并,把全部 IDAT 块合并,然后重新 binwalk 。
提取出来的东西 还是没有 flag !
仔细检查提取的文件,发现 D6E 实际上是 png 的文件头,改后缀名之后,终于拿到 flag 了。
这道题目看了 wp ,实在是没想到合并 IDAT 块,而且有些师傅的 wp 说直接 binwalk 提取就可以了,我怎么感觉写的不是一道题目 qwq 。还有些师傅说可以用 zsteg 做,我还没有试过。
misc18 实际上用 010 打开之后搜索就能找到。
这里我用 exiftool 做的,也是直接就能看到。
ctfshow{325d60c208f728ac17e5f02d4cf5a839}
misc19 一样, 010 里面直接搜就行,分成了两段。
我也是用的 exiftool ,清晰一些。
misc20 exiftool 之后看评论,flag 是个谐音:
ctfshow{c97964b1aecf06e1d79c21ddad593e42}
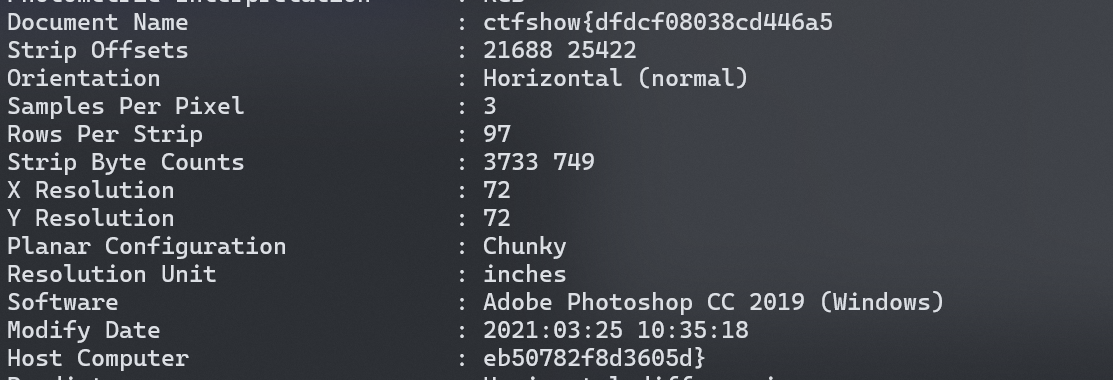
misc21 依旧是 exiftool :
我们可以看到serial number后面有一串数字,这就是我们要找的,但是这不是flag,我们将此转换成ASCII码值,得到这个(hex(X&Ys))。
根据这个提示我们需要依次提取X、Y值(3902939465、2371618619、1082452817、2980145261),我们可以看出这四串数字都是十进制数,我们再将这些数字依次转换成十六进制数,然后我们依次拼接也就是ctfshow{e8a221498d5c073b4084eb51b1a1686d}
misc22 010 里面实际上能找到两个 FF D8 ,但是由于第二个 jpg 文件被加在 exif 元数据里面,binwalk 识别不出来。
这里可以用 010 删数据,也可以用 exiftool -ThumbnailImage -b /misc22.jpg > 123.png 提取缩略图。
misc23 用 exiftool 之后在里面找到 flag 相关线索:
ctfshow{}, UnixTimestamp, DECtoHEX, getflag
unix时间戳转成16进制
flag{03425649ea0e31938808c0de51b70ce6a}
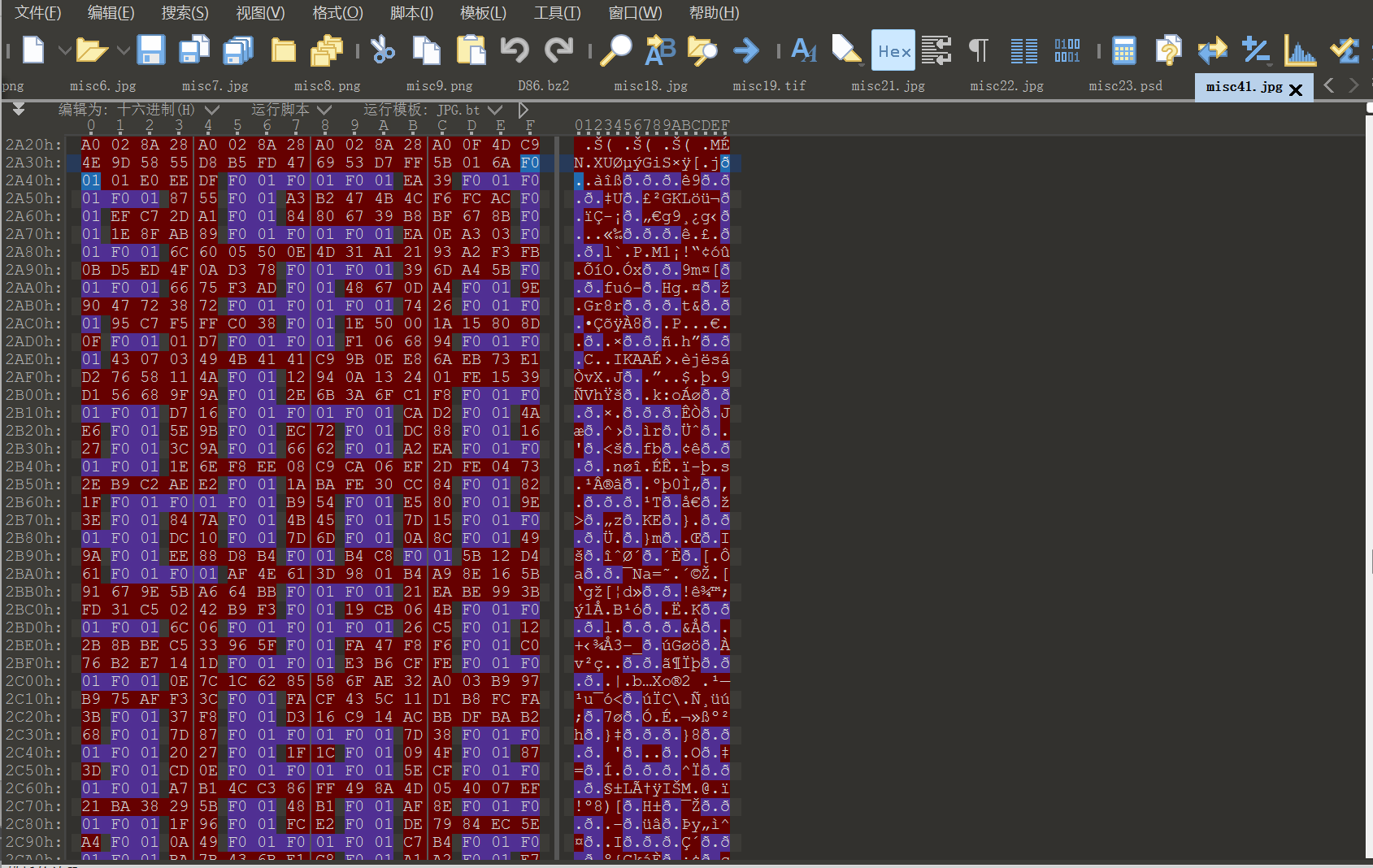
misc41 这题目真气笑了。不愧是愚人节特供。
在 010 里面用 hex 搜索 F001 ,高亮部分就是 flag 。
misc24 根据提示,flag 在图片上面,猜想要更改图片高度。
更改 struct BITMAPINFOHEADER bmih / LONG biHeight 的值:
原来的图片出现 flag:
misc25 还是更改图片高度,flag 在图片下方:
misc 26 改了图片高度之后发现要拿到图片实际高度:
用脚本爆破:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import zlibimport structimport sys1 ]with open (file_path, 'rb' ) as f:int (all_b[29 :33 ].hex (), 16 )bytearray (all_b[12 :29 ])4096 for w in range (n):bytearray (struct.pack('>i' , w))for h in range (n):bytearray (struct.pack('>i' , h))for x in range (4 ):4 ] = width[x]8 ] = height[x]if crc32result == crc32key:print (f"w: {w} , h: {h} " )print (f"hex w: {hex (w)} , hex h: {hex (h)} " )0 )
得到真实高度:
misc27 也是改高度
misc28 gif 改高度,和 png 差不多
misc29 也是 gif 改高度,把每一帧的高度即 image height 都改之后,能在第八帧拿到 flag 。
misc30 ?
题目提示正确宽度是 950 ,把 bmp 图片宽度改一下就有 flag 了。
misc31 已知高度和文件,求实际宽度
但是是个 bmp 文件,也就是说不能用 CRC 来解了。
查了资料, bmp 规定,图片中每一行像素数据所占用的字节数,必须是 4 的倍数。
Row_Size = math.floor((Width * bpp + 31) / 32) * 4
所以用下面脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import sysimport os1 ]with open (file_path, 'rb' ) as f:int .from_bytes(data[10 :14 ], byteorder='little' )int .from_bytes(data[22 :26 ], byteorder='little' )int .from_bytes(data[28 :30 ], byteorder='little' )print (f"[*] 实际文件大小: {actual_size} 字节" )print (f"[*] 像素数据偏移: {data_offset} " )print (f"[*] 已知高度: {height} " )print (f"[*] 色深(bpp): {bpp} " )print ("-" * 30 )False for w in range (1 , 10000 ):31 ) // 32 ) * 4 if expected_size == actual_size:print (f"[+] 找到精确匹配的宽度: {w} (十六进制: {hex (w)} )" )True if not found:print ("[-] 没有找到精确匹配的宽度!" )print ("[-] 正在尝试忽略末尾可能的附加隐藏数据进行推算..." )print ("-" * 30 )if max_row_size > 0 :for w in range (1 , 10000 ):31 ) // 32 ) * 4 if row_size == max_row_size:print (f"[?] 忽略末尾附加数据,推算可能的宽度: {w} (十六进制: {hex (w)} )" )
拿到宽度是 1082 ,最后得到 flag 。
misc32 这题就是 png 图片的宽度,用 CRC 就好了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import zlibimport structimport sys1 ]with open (file_path, 'rb' ) as f:int (all_b[29 :33 ].hex (), 16 )bytearray (all_b[12 :29 ])for w in range (10000 ):bytearray (struct.pack('>i' , w))for x in range (4 ):4 ] = width[x]if crc32result == crc32key:print (f"w: {w} " )print (f"hex w: {hex (w)} " )0 )
拿到宽度是 1044 ,修改后得到 flag 。
misc33 嗯,出题人把宽高都改了,要同时爆破宽高了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import zlibimport structimport sys1 ]with open (file_path, 'rb' ) as f:int (all_b[29 :33 ].hex (), 16 )bytearray (all_b[12 :29 ])for w in range (1 , 4096 ):bytearray (struct.pack('>i' , w))for h in range (1 , 4096 ):bytearray (struct.pack('>i' , h))for x in range (4 ):4 ] = width[x]8 ] = height[x]if crc32result == crc32key:print (f"w: {w} , h: {h} " )print (f"hex w: {hex (w)} , hex h: {hex (h)} " )0 )
得到:w: 978, h: 142
然后拿到 flag 。
misc34 这题出题人把 CRC 也改了,那我们需要考虑 IDAT 数据块
图片所有的像素数据都经过 Zlib 压缩后存在 IDAT 数据块里。只要我们把这些 IDAT 数据提取出来并解压,得到的就是原始的、未经压缩的像素数据总和。这个解压后的数据总长度与图片的宽度、高度有着绝对的数学关系 。
$$\text{Total Length} = \text{Height} \times (1 + \lfloor \frac{\text{Width} \times \text{bpp} + 7}{8} \rfloor)$$
因为解压后的总长度(Total Length)和每个像素占据的位数(bpp,可以从 IHDR 读出)都是已知的,我们只需要让宽度从 901 开始递增。算出每一行应该占用的字节数后,去去除总长度。如果能整除,除出来的结果就是高度!
脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import structimport zlibimport sys1 ]with open (file_path, 'rb' ) as f:24 ]25 ]0 : 1 , 2 : 3 , 3 : 1 , 4 : 2 , 6 : 4 }bytearray ()8 while offset < len (data):'>I' , data[offset:offset+4 ])[0 ]4 :offset+8 ]if chunk_type == b'IDAT' :8 :offset+8 +length])elif chunk_type == b'IEND' :break 12 + lengthlen (raw_pixels)for w in range (901 , 10000 ): //题目信息大于900 1 + (w * bpp + 7 ) // 8 if total_len % row_bytes == 0 :print (f"w: {w} , hex w: {hex (w)} " )print (f"h: {h} , hex h: {hex (h)} " )
得到:
w: 1123, hex w: 0x463
最后拿到 flag 。
misc35 啧,是 jpg 的,它没有之前那些能够严谨推出宽高的,只能用脚本生成多个图片观察。
固定一个比较大的高度值,防止被截断,然后测试宽度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import osimport sys1 ]with open (file_path, 'rb' ) as f:bytearray (f.read())1 for i in range (len (data) - 1 ):if data[i] == 0xFF and data[i+1 ] == 0xC0 :break if sof0_offset == -1 :"jpg_bruteforce" if not os.path.exists(out_dir):2000 5 ] = (fixed_height >> 8 ) & 0xFF 6 ] = fixed_height & 0xFF for w in range (901 , 2000 ):7 ] = (w >> 8 ) & 0xFF 8 ] = w & 0xFF f"w_{w} .jpg" )with open (out_path, 'wb' ) as out_f:
观察后得到宽度为 993 时,得到 flag 。
misc36 我去,是 gif 的,那只能和 jpg 一样了
不过 gif 需要修改每一帧的宽高:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import osimport sys1 ]with open (file_path, 'rb' ) as f:bytearray (f.read())"gif_frames_bruteforce" if not os.path.exists(out_dir):6 :8 ]8 :10 ]2000 bytes ([fixed_height & 0xFF , (fixed_height >> 8 ) & 0xFF ])for w in range (920 , 951 ):bytearray (original_data)bytes ([w & 0xFF , (w >> 8 ) & 0xFF ])6 :8 ] = fw_b8 :10 ] = fh_bfor i in range (len (data) - 10 ):if data[i] == 0x2C and data[i+5 :i+7 ] == orig_w_b and data[i+7 :i+9 ] == orig_h_b:5 :i+7 ] = fw_b7 :i+9 ] = fh_bf"w_{w} .gif" )with open (out_path, 'wb' ) as out_f:
宽度是 941.
misc37 flag 被拆分成多段在 gif 画面中,提取每一帧画面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import sysimport osfrom PIL import Image1 ]open (file_path)"gif_frames_extracted" if not os.path.exists(out_dir):0 try :while True :f"frame_{frame_num} .png" )1 except EOFError:pass
即可拿到 flag 。
misc38 png 文件,常规的 010 发现这个图片很大,用 binwalk 打开里面一堆的 zlib
放到浏览器查看发现图片闪过 flag
查询资料发现这实际上是一个 APNG 文件,它能和 gif 一样存储动画,但是清晰度更高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import sysimport osfrom PIL import Imageif len (sys.argv) < 2 :print ("Usage: python extract_apng_frames.py <your_image.png>" )1 )1 ]if not os.path.exists(file_path):print (f"File not found: {file_path} " )1 )try :open (file_path)except Exception as e:print (f"Error opening image: {e} " )1 )"apng_frames_extracted" if not os.path.exists(out_dir):print (f"[*] 正在分析 APNG 文件: {file_path} " )print (f"[*] 准备提取所有帧到目录: {out_dir} " )0 try :while True :if frame.mode != 'RGBA' :'RGBA' )f"frame_{frame_num} .png" )print (f"[+] 成功提取第 {frame_num} 帧: {out_path} " )1 except EOFError:print ("-" * 30 )print (f"[*] 提取完成!共提取了 {frame_num} 帧画面。" )except Exception as e:print (f"[-] 提取第 {frame_num} 帧时出错: {e} " )
提取每一帧画面,拼接后得到 flag 。
misc39 是个 gif 文件,看不出什么异常。
!!!
gif 的延迟时间这里只有两种,370 毫秒和 360 毫秒,然后分别用 0,1 代替之后,ascii 转可见字符,得到 flag
!!!
想不到,这个让我幻视之前一道压缩包的题目了
就是压缩包的 deflate 方法只用了两种,然后也是转成 0,1 得到的flag
下面的脚本来自 ctfshow 的 qscf1234 的 wp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from PIL import Image, ImageSequencer'misc39.gif' '' with Image.open (gif_path) as img:'duration' ] print (f"Global delay: {global_delay} milliseconds" )for frame in ImageSequence.Iterator(img):'duration' ] if delay:if delay==370 :'1' elif delay==360 :'0' else :print ('异常' )else :pass print (delay_time_flag)'' for i in range (0 , len (delay_time_flag), 7 ):chr (int (delay_time_flag[i:i+7 ], 2 ))print (flag)
misc40 是 APNG 图片,和上一题差不多,拿到延迟分子转成可见字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import sysimport struct1 ]with open (file_path, 'rb' ) as f:"" 0 while True :b'fcTL' , offset)if idx == -1 :break '>H' , data[idx+24 :idx+26 ])[0 ]try :if delay_num > 0 :chr (delay_num)except ValueError:pass 4 print (result)
结果:
å¥å¨ç¼åï¼çé½ä¸åctfshow{95ca0297dff0f6b1bdaca394a6fcb95b}
前面一串乱码发现实际上是一段套娃编码
对应的数是: 229, 165, 151, 229, 168, 131, 231, 188, 157, 229, 144, 136, 239, 188, 140, 231, 139, 151, 233, 131, 189, 228, 184, 141, 229, 129, 154
首先,把以上数字(Unicode编码10进制)都转换为16进制,在随波逐流里,(Unicode编码10进制)>>>(字符)>>>(16进制)
e5 a5 97 e5 a8 83 e7 bc 9d e5 90 88 ef bc 8c e7 8b 97 e9 83 bd e4 b8 8d e5 81 9a
三数为一组,字母变大写
E5A597 ,E5A883 ,E7BC9D ,E59088 ,EFBC8C ,E78B97 ,E983BD ,E4B88D ,E5819A
最后的文字:套娃缝合,狗都不做
misc42 png 文件,学乖了先看它是不是 APNG ,发现不是,于是常规的 binwalk ,010,tweakpng
发现它有一堆 IDAT 数据块,再结合题目说 flag 长度是 41 位,考虑 IDAT 长度隐写
把每个 IDAT 的长度拿到之后转为可见字符,得到 flag 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import sysimport struct1 ]with open (file_path, 'rb' ) as f:8 )"" while True :4 )if not len_bytes or len (len_bytes) < 4 :break '>I' , len_bytes)[0 ]4 )if chunk_type == b'IDAT' :try :chr (length)except ValueError:pass elif chunk_type == b'IEND' :break 4 )print (result)
得到å¿å¿1ctfshow{078cbd0f9c8d3f2158e70529f8913c65}
misc43 一番常规流程查看,发现 tweakpng 一直弹出 IDAT 块报错,所以可能是要 CRC32 拼接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import sysimport struct1 ]with open (file_path, 'rb' ) as f:8 )b"" while True :4 )if not len_bytes or len (len_bytes) < 4 :break '>I' , len_bytes)[0 ]4 )4 )if chunk_type == b'IEND' :break print (result.decode('ascii' , errors='ignore' ))
拿到:a.ctfshow{6eb2589ffff5e390fe6b87504dbc0892}B`